


TLTD #21 - The personality of AI Systems
How Post-Training Shapes AI Behaviour

What shapes the personality of you favourite AI?
Last week, when I posted about DeepSeek and its apparent censorship, I realised that perhaps the way Large Language Models (LLMs) answer our questions isn’t well understood beyond the more technical community, so I thought I’d shed light on what it takes to give an LLM its personality.

If you missed my LinkedIn post, I tested DeepSeek in two different environments and got very different responses to the same question. This led me down a rabbit hole about how AI models develop their personalities.
Beyond Initial Training
Most people would have a rough intuition that LLMs are trained on vast amounts of data from diverse sources, and that’s why they’re so impressive — this is partially true. The full training process is quite involved, as you can see in the simplified high-level image below:

However, if researchers stopped at the training stage, models like GPT, Claude, Gemini and others would do little more than just finish off our sentences.
This is where post-training kicks in. Post-training is where the model is taught how to interact with users in a conversational way, handle certain types of tasks and even have certain preferences!
How Post-Training Works
Let's go a bit deeper into each aspect of post-training and how they work:
1. Instruction Tuning
At this stage you have an LLM that knows a lot of things but doesn’t necessarily know how to put that knowledge to use in helpful ways. Instruction tuning teaches the model how to recognise and follow specific commands, focusing on contextually relevant and coherent responses. It’s done through carefully curated prompt-response pairs. Here’s what these look like:
Prompt: "Summarise this article in three sentences"
Response: "Here's a three-sentence summary of the article..."
Prompt: "Write a professional email to decline a meeting"
Response: "Thank you for the invitation. Unfortunately..."
The model learns from thousands of these pairs, gradually understanding how to respond appropriately to different types of requests and tasks. It’s like teaching it how to have a conversation by feeding it a large collection of scenarios.
2. Preference Alignment
Preference alignment on the other hand makes sure LLMs generate outputs that align with human values and expectations. The idea is to make their responses more helpful, safe, and engaging. Human preference alignment is done in two key ways: Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimisation (DPO) .

Reinforcement Learning from Human Feedback (RLHF)
This is the more widely used approach that gave us ChatGPT. Think of it as an apprenticeship model:
## Step 1: Generate Multiple Responses
Prompt: "How do computers work?"
Model generates multiple responses:
Response A: "Computers process information using binary..."
Response B: "Let me explain that step by step..."
## Step 2: Human Feedback
Human raters rank these responses based on quality, clarity, and usefulness.
## Step 3: Reward Learning
The model learns a "reward function" from these human preferences.
## Step 4: Policy Optimisation
The model is fine-tuned to maximise this learned reward function.
This process is very powerful and flexible but is also more time consuming, expensive and difficult to get right.
Direct Preference Optimisation (DPO)
DPO is the new kid on the block due to being a cheaper and simpler alternative. Instead of the complex reward learning process, it directly teaches the model to prefer certain responses:
Prompt: "What is the capital of France?"
Chosen Response: "Paris"
Rejected Response: "I don't know."
Prompt: "Explain photosynthesis"
Chosen Response: "Photosynthesis is how plants convert sunlight into energy."
Rejected Response: "Plants eat sunlight to grow."
After being trained on thousands of such prompt-response pairs in Instruction Tuning and Preference Alignment, the model learns to recognise a wide range of tasks and themes and how to respond to them.
3. Safety Guardrails
Safety guardrails can come in two flavours: embedded safety and external safety.
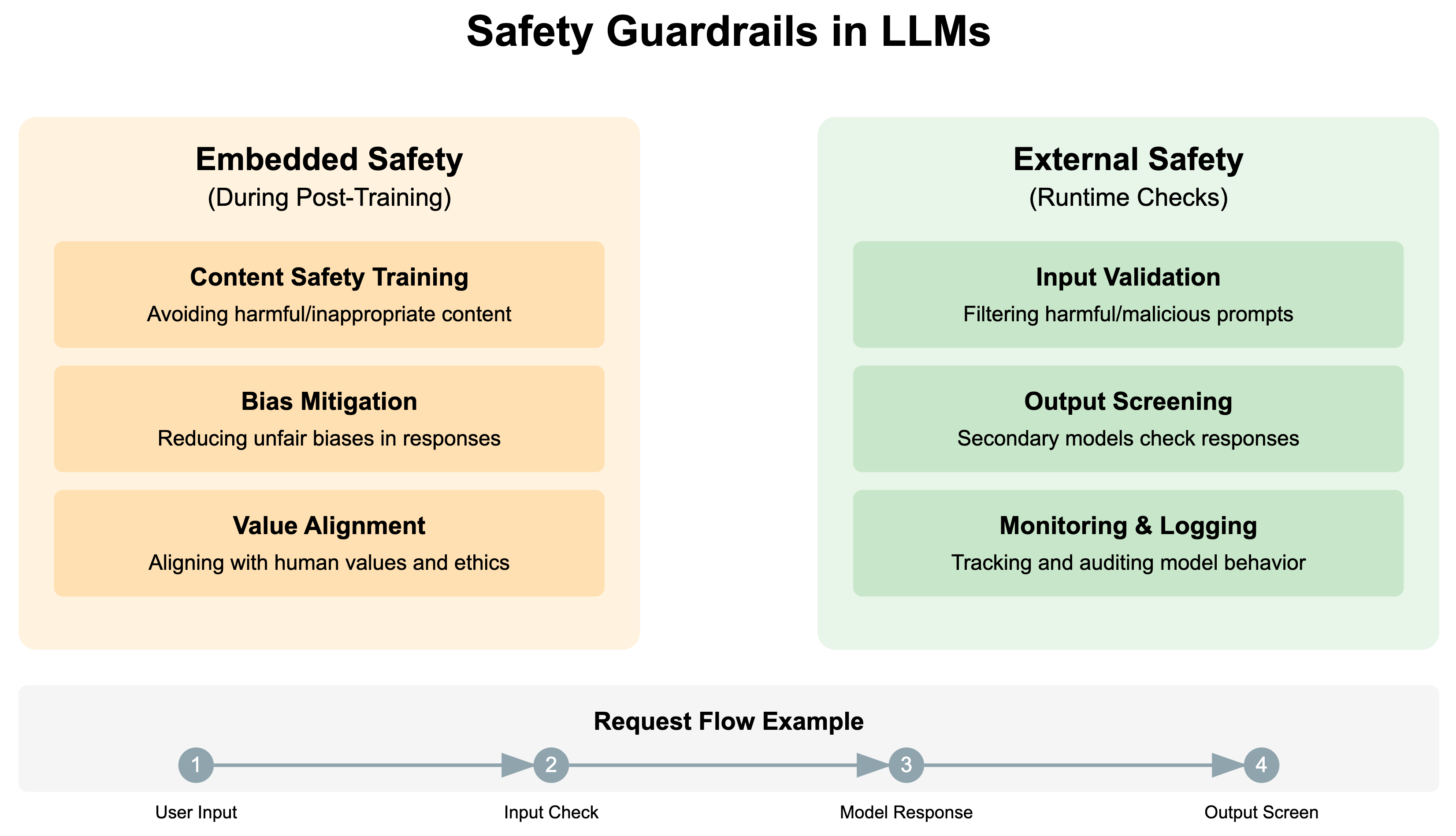
Embedded safety happens during pretraining as we have seen earlier in the article while external safety is done through a mix of secondary models and APIs. Both approaches are usually used to ensure the model is safe for public consumption. These guardrails are used to evaluate not only user input but also the outputs of the models, before they are displayed to a user.
I won’t go into much detail here beyond saying that these additional checks evaluate potential responses across multiple dimensions:
Content safety (violence, explicit content)
Information accuracy
Potential for misuse
Cultural sensitivity
Post-Training vs Fine-Tuning: These are basically the same thing from a technical standpoint. However, post-training usually refers to fine-tuning done by the model developer — i.e. OpenAI fine-tuning GPT. Fine-tuning, then, refers to 3rd party companies customising the model to their own needs — i.e.: a telecommunications company fine-tuning Llama to improve performance in that domain by training it on proprietary datasets.
Why should we care?
Understanding the nuances of how models are trained and how its preferences align to yours and your organisation’s goals is important in order to choose the right trade-offs when deploying AI at scale:
Tool Selection
Can you customise the instruction tuning for your own use cases?
Do the model’s preferences align with your organisation’s values?
Are the safety guardrails appropriate for your context and regulatory environment?
Risk Management
How do you validate the model’s behaviour across different scenarios?
What monitoring do you need to ensure consistent alignment?
How do you handle edge cases where the model’s learning conflicts with business needs?
Training doesn’t stop here
Post-training techniques are still an emerging area and we’re seeing new approaches. I’ve linked some resources below for those interested in more details:
Interactive alignment learning: This technique refines language models through continuous interaction, enabling them to better align with human behaviors and preferences by learning from real-time human feedback. [1] [2]
Multi-stakeholder preference learning: This approach aligns language models to cater to the diverse preferences of various stakeholder groups, ensuring the model’s outputs are tailored to meet the specific needs and values of different communities. [1] [2]
Cultural adaptation layers: This method involves adapting language models to specific cultural contexts by incorporating culturally specific knowledge and safety values, enhancing the model’s relevance and safety across different regions. [1] [2]
I expect we’ll see some standardisation over time. The challenge will be balancing consistency with flexibility across different contexts. Model evaluation becomes even more crucial given the breadth of what modern LLMs can do.
How much thought are you and your teams putting into model selection and human preference alignment? Have you encountered situations where the way a model responded to your users was surprising or unexpected? Let me know in the comments!